- Machine Learning Concepts – Part 1 – Deployment Introduction
- Machine Learning Concepts – Part 2 – Problem Definition and Data Collection
- Machine Learning Concepts – Part 3 – Data Preprocessing
- Machine Learning Concepts – Part 4 – Exploratory Data Analysis
- Machine Learning Concepts – Part 5 – Model Selection
- Machine Learning Concepts – Part 6 – Model Training
- Machine Learning Concepts – Part 7 – Hyperparameter Tuning
- Machine Learning Concepts – Part 8 – Model Evaluation
Previously, we gave an introduction to the necessary steps to deploy a machine learning model as well as started the discussion of problem definition and data collection. Now that we have a firm understanding of the problem our machine learning model is attempting to solve we need to perform a number of actions to prepare the data for use within our model. This is a crucial step in the development of your machine learning model and, for many, should be the step that they spend the most time in.
1. Cleaning
Unless you’re working with a prepared dataset you’ll need to “clean” the data before using it to train our machine learning model. This is necessary in order to provide our model with data that provides consistency.
1.1. Handling Missing Values
Missing values will probably be the most common data inconsistency that you’ll need to attend to. In general, we don’t care about missing values as long as there is enough data for our ML model that is not missing.
- Deletion – Remove rows or columns with missing data. If not enough data is present to properly train our machine learning model we should simply consider deleting the data from our dataset.
- Imputation – In statistics, imputation is simply the process of replacing missing or invalid data with substitute values. This could be as simple as replacing empty data points with a None value
1.2. Removing Duplicates
Duplicates reinforce repeat patterns of the training data by our large language model leading to overfitting. Overfitting will cause our large language model to perform well against training data, but will struggle with new, unseen data. Other reasons why removing duplicates is important, include:
- Improving Generalization – Removing duplicates exposes our model to a more diverse range of examples. Improving generalization will lead to our model performing better when encountering novel inputs.
- Ensuring Unique Information – Focusing on unique data points allows our model to have a more comprehensive understanding of the language that it’s being trained on.
- Data Integrity – Duplicates may indicate errors in data collection or processing. Identifying and removing duplicates ensures that duplicates are not the result of processing errors.
- Computational Efficiency – Processing duplicate data is simply a waste of computational resources.
1.3. Correcting Inconsistent Formatting
Large language models rely on numerical representations of data or specific data structures. Inconsistent formatting can prevent our model from properly interpreting the data. Consider the following data types that may have various ways of formatting.
- Dates and Times
- Capitalization
- Units of Measurement
- Currency Symbols
- Special Characters and Punctuation
1.4. Outlier Detection and Handling
Identify extreme values that might be errors or anomalies. Decide whether to remove them, cap them, or transform them using techniques like logarithmic transformation. Outliers can significantly distort our model’s learning and lead to inaccurate predictions.
1.4.1. Detection Methods
The following methods can assist with determining outliers in our data:
- Visualization – Box plots, scatter plots, and histograms can visually reveal potential outliers.
- Z-score – Measures how many standard deviations a data point is from the mean. Z-scores above a certain threshold are considered outliers.
- Interquartile Range (IQR) – Outliers are 1.5x the IQR before the first quartile or above the third quartile.
- Modified Z-score – Similar to standard Z-score but is less sensitive to more extreme values.
1.4.2. Treatment Options
Now that we’ve identified potential outliers we need to decide how to treat them.
- Removal – If outliers are clearly an error, removal is a valid option. Removal of too many data points may lead to information loss and model bias.
- Capping – Replace outliers with a predefined minimum or maximum value that limits the influence of a data point on our model.
- Transformation – Transforming the data point may be a valid option for handling outliers. Transformation functions include Logarithmic Transformation and Box-Cox Transformation.
When determining how to best handle outliers it’s important to consider the nature of outliers, impact on model performance, and domain expertise (aka your understanding of the data and the problem).
2. Transformation
2.1 What is a Feature?
Before we dive into transformations a little more we should explain features. A feature is a measurable property or characteristic of your data. Features are used your machine learning algorithm to learn patterns and make predictions. Some examples of features include the presence of a shape or color, a demographic such as age, location, or anything else that you’d use to categorize your data.
2.2 Feature Scaling
Feature scaling is used to ensure that every feature in our model is on the same scale. This ensures that our model will treat similar features equally. This is one way to help reduce bias in our model.
- Standardization –The purpose of standardization is to re-scale features to ensure that the mean and the standard deviation are 0 and 1, respectively. This is useful, and necessary, for the optimizing our algorithms.
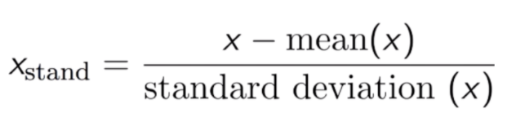
- Normalization –Normalization is a technique that re-scales the features in our data with a distributed value between 0 and 1. For each feature, the minimum value of that feature is assigned a 0, and the maximum value of that feature is assigned a 1.
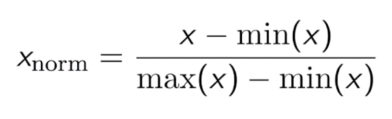
2.3 Encoding Categorical Variables
Categorized data must be converted into a numerical format that our machine learning algorithm can use. Here are a couple of methods to perform such a feat.
- One-Hot Encoding – A new binary column is created for each unique category. The column will contain a
1if the row’s data matches the corresponding category, or a0if it does not. If you have a lot of categorizations, you’ll end up with a lot of columns. - Label Encoding – With label encoding a unique integer is used to represent each unique category. As you can imagine, label encoding requires the creation of fewer columns, but may also be more difficult when dealing with multiple integer assignments.
Label encoding is generally preferred when there is a meaningful ordinal relationship between categories. However, bias may result if the ordinality is not genuine.
3. Feature Engineering
Now that we’ve cleaned up our data and understand what features are we now need to use these features to help our algorithm to learn more effectively by ensuring that our model understands the relationships between features.
- Combining Features (aka Interaction Terms) – Interaction terms dictate how one feature may effect or depend on another feature.
- Polynomial Features – Not all data has a linear relationship. Polynomial features allow the modeling of curved or non-linear patterns.
- Domain Expertise – Understanding the specific problem domain is invaluable. Having an understanding of relevant factors that are not explicitly captured in raw data will help you to understand the outputs, as well as to engineer features from raw data that may not be obvious.
Not all features are going to be equally as useful. Take the time to identify the most important features to your model and remember, feature engineering is an iterative process!
4. Document
Always document preprocessing steps as clearly as possible in order to reproduce results, as well as to understand how the data was transformed. This should include each step of pre-processing that is performed on our data including details on transformations, and rationale for data removals and/or caps.
5. Conclusion
An important thing to remember is that the data preprocessing step is an iterative process which allows you to experiment with a different number, and combination, of techniques in order to allow you to find what works best for your dataset and ML problem.