
Every couple of years a new or evolving technology bring about a whole new set of buzzwords that are often misunderstood by the general public. First, we saw the advent of the “cloud”, which is still not very well understood by most. We followed that up with Machine Learning (M.L.), and today we are constantly hearing about Artificial Intelligence (A.I.) and how it’s going to take over our jobs or how it’s being used to produce realistic threats. But, what are we talking about when we use the term, “Artificial Intelligence”, and what are some of the real-world impacts?
What is Artificial Intelligence?
A.I. is the term used when technology is capable of performing cognitive functions that we normally associate with human thinking. Cognitive functions, or skills, are brain-based skills that allow humans to acquire and manipulate new information. Cognitive skills encompass the domains of perception, attention, memory, learning, decision making, and language abilities. As you can imagine these domains are essential to how we, as cognitive beings, operate and evolve.
A.I. is an attempt to replicate the complicated cognitive functions in our brain by using a variety of information models that are continuously processing large amounts of data in order to identify and continuously recognize certain patterns. For example, if you were to provide an A.I. information model 1,000 pictures of different types of Apples, cut in different ways, with different colors; the information model would identify what “patterns” make up an Apple. When applied to other pictures of Apples, the information model, would still recognize the pattern, or patterns, of an Apple.
This is obviously a rudimentary example of how an information models work, but the same scenario can be applied to written text instead of pictures of Apple’s.
Limitations of Artificial Intelligence
As with any technology, A.I. has its limitations.
Data
The information models that are used by A.I. are only as reliable as the data being used to train that model. Due to the significant amount of data that is required to train information models, developers utilize the biggest data repository of all time. That data repository? The Internet. As you can imagine, not all data available on the Internet is relevant or even accurate. This makes it very difficult, and even impossible, to guarantee the accuracy of what A.I. is producing.
Bias & Discrimination
As much as we’d all like to admit that we can be 100% objective, it simply isn’t possible. Every human-being on earth carries a level of bias, not because we’re all prejudice, but because we’ve all lived different lives, from different perspectives, from all over the world. Bias is a part of the human experience, however that same bias can end up in the software that we develop. A.I. shouldn’t have bias, but as long as it’s being developed by individuals with bias, and being trained with data created by individuals with bias, A.I. will continue to be bias.
Ethics / Privacy
Currently, several countries have banned ChatGPT either because of privacy concerns, or as a way to spread “misinformation”. Several Canadian provinces have also come together to investigate whether OpenAI received “valid and meaningful” information-sharing consent by Canadian users. PIPEDA is the Canadian legislation that, among other things, requires private organizations to obtain valid and meaningful consent to collect, use, and/or disseminate personal information of Canadians.
Many modern countries and jurisdictions have similar laws and regulations that may hamper the ability for A.I. information models to use the data of residents.
Compute Time / Cost
It takes a lot of compute time (and power) for information models to be continuously processing data. This doesn’t even include the compute power required for generative A.I. to be processing and handling requests from users. Although cloud services provide essential, and extensional services, it still comes at a very high cost.
Human Cognition
Simply put, information models fail to replicate the precision and depth of very complex human cognitive skills. This includes an ability to factor in emotion, which is also key factor in how we evolve.
Attack Vectors of Artificial Intelligence
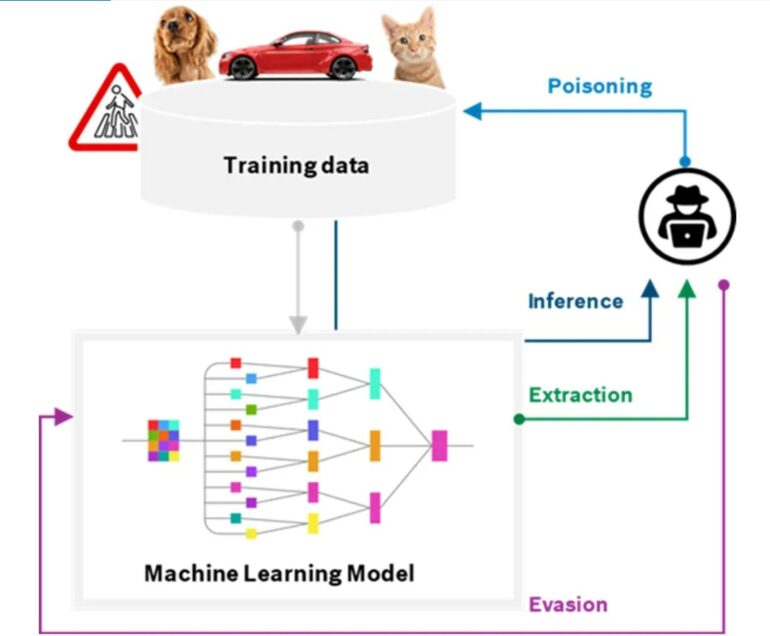
For every limitation that exists with Artificial Intelligence, threat actors have an opportunity to take advantage of the technology to do something that the technology wasn’t intended, or built, to do. Let’s discuss some examples of attacks against Artificial Intelligence.
Poisoning
Split-View Poisoning
Split-view poisoning occurs when the data used by an information model is changed after the information model is trained. Due to must information models being trained on publicly available Internet data, it would be possible for a threat actor to identify a website being used by an information model, buy the domain name, and change the content. This could lead to an A.I. serving up malicious content or information, as well as misinformation, if they were to control enough of the content that the information model is trained on.
Front-Running Attack
Front-running attacks involve a threat actor utilizing legitimate means to update website content being used to train an information model. Wikipedia provides snapshots of it’s articles in order to deter bots from crawling the site. It is possible to see when a Wiki article will be “snapshotted”. If a threat actor were to update many Wiki articles with malicious content, before the snapshot is performed. The information model using that content may be trained with the malicious content.
Camera streams that utilize A.I. may also be susceptible to front-running attacks. Imagine that you had a video camera pointing at your front yard and capturing sidewalk traffic. A threat actor may perform a front-running attack against the camera stream by introducing various objects and/or movements that may lead the A.I. model to perform in unexpected ways.
Inference/Model Inversion
An inference attack is a data loss event whereby a threat actor queries the A.I. model for specific information that may indicate the existence of a specific piece of data. This could reveal the underlying dataset, which could allow the threat actor to reproduce the training data, and possibly accessing sensitive or private data.
Evasion
Evasion involves the threat actor designing an input for an A.I. model that might be identifiable by a human-being, but is wrongly classified by an A.I. model. A wrongly trained A.I. model can have it’s security features bypassed.
Extraction
Extraction, as the name suggests, is when a threat actor probes an A.I. system in order to extract data from it that will help the threat actor reconstruct the data model, or even steal sensitive data. As mentioned, Artificial Intelligence is only as reliable as the data models that we introduce to it.
Threat Modeling Artificial Intelligence
Microsoft has provided an excellent article on Threat Modeling AI/ML Systems and Dependencies that contains specific questions which allow you to identify possible threats to your A.I./M.L. systems.
References
- https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-ai
- https://en.wikipedia.org/wiki/Cognitive_skill
- https://viso.ai/deep-learning/ml-ai-models/
- https://hbr.org/2019/10/what-do-we-do-about-the-biases-in-ai
- https://www.digitaltrends.com/computing/these-countries-chatgpt-banned/
- https://www.cbc.ca/news/canada/british-columbia/canada-privacy-investigation-chatgpt-1.6854468
- https://www.priv.gc.ca/en/privacy-topics/privacy-laws-in-canada/the-personal-information-protection-and-electronic-documents-act-pipeda/pipeda_brief/
- https://spectrum.ieee.org/ai-cybersecurity-data-poisoning
- https://www.cyber.gc.ca/en/guidance/artificial-intelligence-itsap00040
- https://learn.microsoft.com/en-us/security/engineering/threat-modeling-aiml
- https://towardsdatascience.com/how-to-attack-machine-learning-evasion-poisoning-inference-trojans-backdoors-a7cb5832595c
- https://ai-infrastructure.org/understanding-types-of-ai-attacks/